
1 MySQL體系結(jié)構(gòu)
1.1 數(shù)據(jù)庫(kù)與數(shù)據(jù)庫(kù)實(shí)例
數(shù)據(jù)庫(kù):物理操作系統(tǒng)中的文件和其他文件類型的集合,除了硬盤存儲(chǔ)的文件,也可以是存放在內(nèi)存中的文件
數(shù)據(jù)庫(kù)實(shí)例:有數(shù)據(jù)庫(kù)后臺(tái)進(jìn)程、線程以及一個(gè)共享內(nèi)存區(qū)域組成,共享內(nèi)存可以被后臺(tái)進(jìn)程/線程所共享,是應(yīng)用程序,位于用戶與操作系統(tǒng)直接的數(shù)據(jù)管理軟件
注意:不能通過(guò)修改二進(jìn)制文件來(lái)更改數(shù)據(jù)庫(kù)內(nèi)容,僅可以通過(guò)數(shù)據(jù)庫(kù)實(shí)例操作數(shù)據(jù)庫(kù)。在MySQL中,實(shí)例與數(shù)據(jù)庫(kù)是一一對(duì)應(yīng)的,但在集群環(huán)境下會(huì)發(fā)生一個(gè)數(shù)據(jù)庫(kù)被多個(gè)實(shí)例調(diào)用的情況
1.2 體系結(jié)構(gòu)
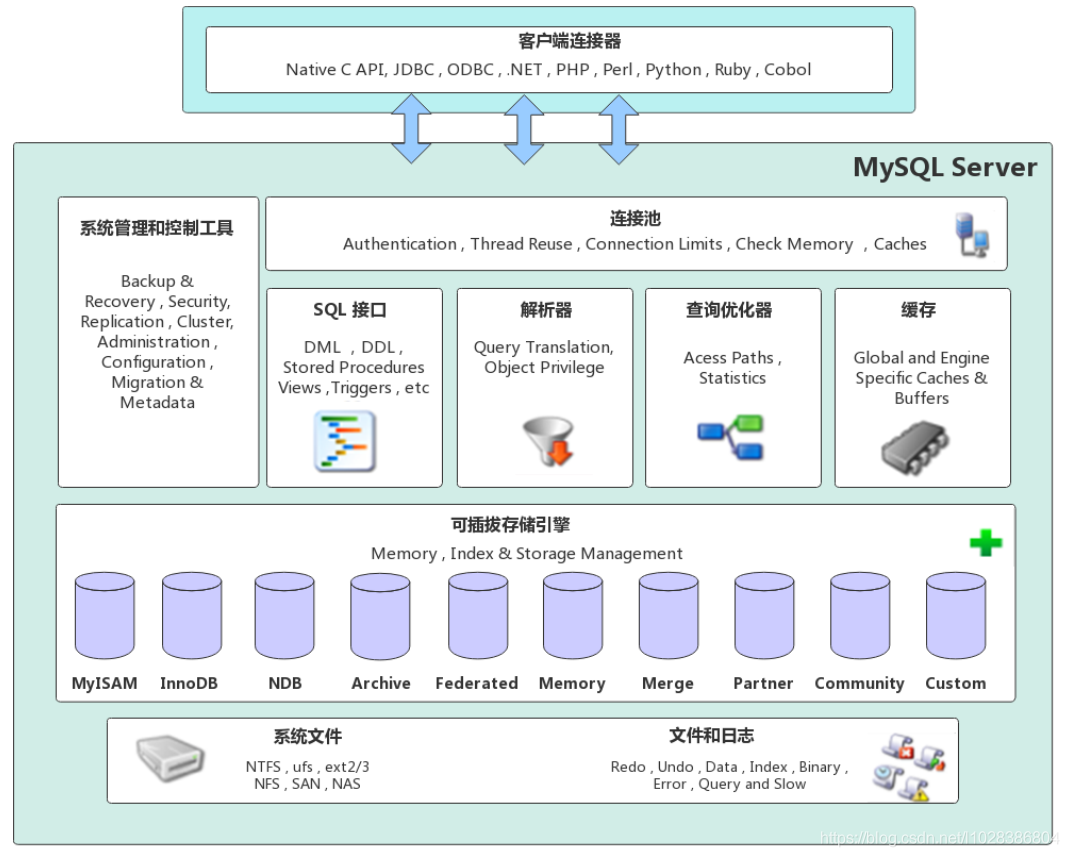
由圖可知,MySQL由以下組件構(gòu)成:
-
連接池組件
-
管理服務(wù)與工具組件
-
SQL接口組件
-
查詢分析器組件
-
優(yōu)化器組件
-
緩存組件
-
插件式存儲(chǔ)引擎
-
物理文件
MySQL的重要特點(diǎn)是其插件式存儲(chǔ)引擎,提供了一系列標(biāo)準(zhǔn)的管理和服務(wù)支持,這些標(biāo)準(zhǔn)與存儲(chǔ)引擎本身無(wú)關(guān),可能是數(shù)據(jù)庫(kù)系統(tǒng)本身所必需的,如SQL分析器和優(yōu)化器等,而存儲(chǔ)引擎是底層物理結(jié)構(gòu)的實(shí)現(xiàn),此外,存儲(chǔ)引擎是基于表的,而不是數(shù)據(jù)庫(kù)
2 常見(jiàn)的存儲(chǔ)引擎
2.1 InnoDB存儲(chǔ)引擎
InnoDB存儲(chǔ)引擎支持事務(wù),是面向在線事務(wù)處理方面的應(yīng)用,支持行鎖、外鍵,支持類似Oracle的非鎖定讀,默認(rèn)情況讀取操作不會(huì)產(chǎn)生鎖,在MySQL5.1版本之后被設(shè)定成默認(rèn)存儲(chǔ)引擎,此前是MyISAM
InnoDB存儲(chǔ)引擎將數(shù)據(jù)放在一個(gè)邏輯表空間,由InnoDB自身進(jìn)行管理,將每個(gè)InnoDB存儲(chǔ)的表單獨(dú)放在一個(gè)獨(dú)立的ibd文件中,同樣也可以使用裸設(shè)備(row disk)建立表空間
InnoDB使用多版本并發(fā)控制(MVCC)獲得高并發(fā)性,實(shí)現(xiàn)了SQL標(biāo)準(zhǔn)的4種隔離級(jí)別,默認(rèn)使用的是REPEATABLE READ(可重復(fù)讀)級(jí)別,此外還提供了插入緩沖、預(yù)讀、二次寫、自適應(yīng)哈希索引、預(yù)讀等高性能和高可用的功能
針對(duì)表數(shù)據(jù)的存儲(chǔ),InnoDB存儲(chǔ)引擎采用了聚集(clustered)的方式,每張表的存儲(chǔ)按照主鍵的順序存放,如果沒(méi)有顯式地指定主鍵,InnoDB將為每一行生成一個(gè)6字節(jié)的ROWID作為主鍵
2.2 MyISAM存儲(chǔ)引擎
特點(diǎn)是不支持事務(wù)、表鎖和全文索引,針對(duì)一些OLAP(在線分析處理)操作速度快,MyISAM存儲(chǔ)引擎表由MYD與MYI組成,MYD用于存放壓縮數(shù)據(jù)文件,MYI用于存放索引文件,可使用myisampack工具壓縮數(shù)據(jù)文件,使用哈夫曼編碼靜態(tài)算法壓縮,輸出結(jié)果為只讀表。在獨(dú)占表空間中,每一個(gè)表還有一個(gè).frm表描述文件,以及一個(gè).ibd文件(這個(gè)文件包括了單獨(dú)一個(gè)表的數(shù)據(jù)內(nèi)容以及索引內(nèi)容)
注意:對(duì)于MyISAM存儲(chǔ)引擎表,MySQL只緩存索引文件,數(shù)據(jù)文件的緩存由操作系統(tǒng)本身完成,這與其他使用LRU算法緩存數(shù)據(jù)的大部分?jǐn)?shù)據(jù)庫(kù)大不相同
2.3 NDB存儲(chǔ)引擎
NDB是一種集群存儲(chǔ)引擎,類似Oracle的RAC share everything結(jié)構(gòu),但不同的是其使用share nothing的集群結(jié)構(gòu),因此能提高更高級(jí)別的高可用性。
NDB的特點(diǎn)是數(shù)據(jù)放置在內(nèi)存中(5.1版本后可將非索引數(shù)據(jù)放在磁盤中),主鍵查找的速度極快,并可以通過(guò)添加NDB數(shù)據(jù)存儲(chǔ)節(jié)點(diǎn)(Data Node)線性的提高存儲(chǔ)性能,可以作為高可用、高性能的集群系統(tǒng)
注:NDB存儲(chǔ)引擎的連接操作是在MySQL數(shù)據(jù)庫(kù)層完成的,而不是在存儲(chǔ)引擎層,意味著需要較大的網(wǎng)絡(luò)開(kāi)銷,因此查詢速度較慢
2.4 Memory存儲(chǔ)引擎
Memory將數(shù)據(jù)存放在內(nèi)存中,如果數(shù)據(jù)庫(kù)重啟或崩潰,所有數(shù)據(jù)將丟失,適合用于存儲(chǔ)臨時(shí)數(shù)據(jù)的臨時(shí)表以及數(shù)據(jù)倉(cāng)庫(kù)中的維度表,默認(rèn)使用哈希索引
該引擎存在一些限制,比如只支持行鎖,并發(fā)性能差,不支持TEXT和BLOB列類型,還有存儲(chǔ)變長(zhǎng)字段是是按照定長(zhǎng)方式進(jìn)行的,存在內(nèi)存浪費(fèi)的問(wèn)題。若存放結(jié)果集時(shí),中間結(jié)果集的大小大于Memory存儲(chǔ)引擎表的容量設(shè)置,或存在TEXT或BLOB字段,MySQL會(huì)將其轉(zhuǎn)化為MyISAM存儲(chǔ)引擎放在磁盤,因MyISAM不緩存數(shù)據(jù)文件,因此產(chǎn)生的臨時(shí)表的性能會(huì)有損失
2.5 Archive存儲(chǔ)引擎
Archive存儲(chǔ)引擎只支持insert和select操作,從MySQL5.1之后支持索引,使用zlib算法壓縮數(shù)據(jù)行后存儲(chǔ),壓縮率可達(dá)到1:10,適用于存儲(chǔ)歸檔數(shù)據(jù),并使用行鎖實(shí)現(xiàn)高并發(fā)的寫入操作
2.6 Federated存儲(chǔ)引擎
Federated存儲(chǔ)引擎不存放數(shù)據(jù),用于指向一臺(tái)遠(yuǎn)程MySQL數(shù)據(jù)庫(kù)服務(wù)器的表,類似SQL Server的鏈接服務(wù)器與Oracle的透明網(wǎng)關(guān),不同的是Federated存儲(chǔ)引擎只支持MySQL數(shù)據(jù)表,不支持異構(gòu)數(shù)據(jù)表
2.7 Maria存儲(chǔ)引擎
Maria存儲(chǔ)引擎是新開(kāi)發(fā)的引擎,目標(biāo)是取代原有的MyISAM存儲(chǔ)引擎,成為MySQL的默認(rèn)存儲(chǔ)引擎,特點(diǎn)是緩存數(shù)據(jù),索引數(shù)據(jù),行鎖設(shè)計(jì),提供MVCC功能,支持事務(wù)和非事務(wù)安全的選項(xiàng)支持,以及更好的BLOB字符類型的處理性能
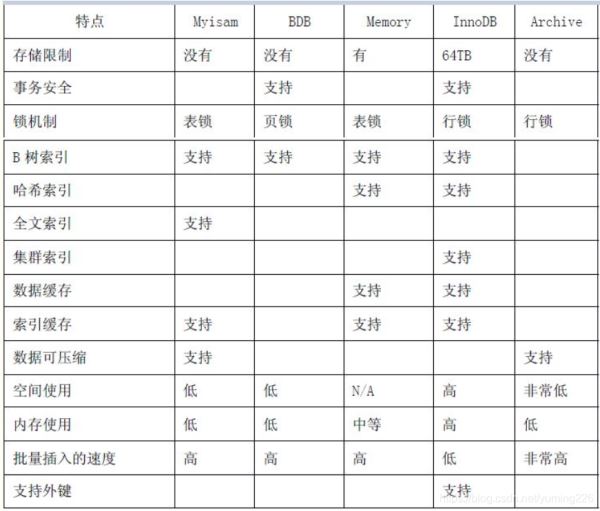
2.8 對(duì)比
3 InnoDB存儲(chǔ)引擎
3.1 概述
InnoDB是事務(wù)安全的MySQL存儲(chǔ)引擎,一般用于核心應(yīng)用表的首先存儲(chǔ)引擎
3.2 體系架構(gòu)
如圖,InnoDB擁有多個(gè)內(nèi)存塊,組成了一個(gè)大的內(nèi)存池,負(fù)責(zé)以下工作:
- 維護(hù)所有進(jìn)程/線程需要訪問(wèn)的多個(gè)內(nèi)部數(shù)據(jù)結(jié)構(gòu)
- 緩存磁盤上的數(shù)據(jù),方便快速讀取,并在對(duì)磁盤文件的數(shù)據(jù)修改之前進(jìn)行緩存
- 重做日志緩沖
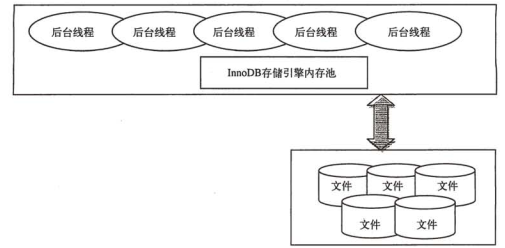
后臺(tái)線程用于刷新內(nèi)存池的數(shù)據(jù),保證緩沖池中的內(nèi)存緩存的是最近的數(shù)據(jù)。此外,將已經(jīng)修改的數(shù)據(jù)刷新到磁盤文件,同時(shí)保證在數(shù)據(jù)庫(kù)發(fā)生異常時(shí)InnoDB能恢復(fù)到正常運(yùn)行狀態(tài)
3.2.1 后臺(tái)線程
-
IO線程
一個(gè)insert buffer線程,一個(gè)log線程,4個(gè)讀線程,4個(gè)寫線程
-
master線程
-
lock監(jiān)控線程
-
錯(cuò)誤監(jiān)控線程
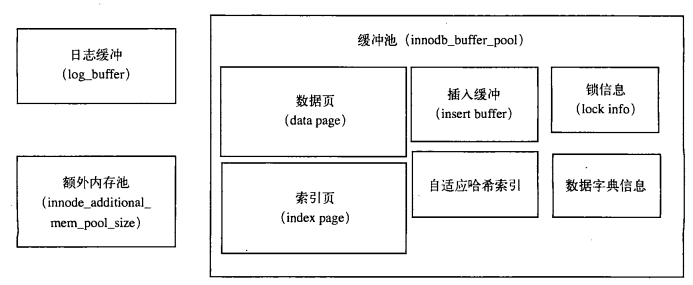
3.2.2 內(nèi)存
內(nèi)存由三部分構(gòu)成,緩沖池(buffer pool)、重做日志緩沖池(redo log buffer)以及額外的內(nèi)存池(additional memory pool),分別由配置文件的參數(shù)innodb_buffer_pool_size和innodb_log_buffer_size的大小決定
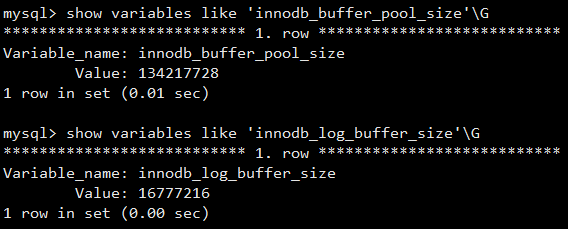
使用 show engine innodb status\G; 可以查看InnoDB緩沖池的使用情況,buffer pool size表示一共有的緩存幀(buffer frame),每個(gè)緩存幀大小為16k,所以一共分配了512M的緩沖池,free buffers表示當(dāng)前空閑的緩沖幀,database pages表示以及使用的緩沖幀,modify db pages表示臟頁(yè)的數(shù)量
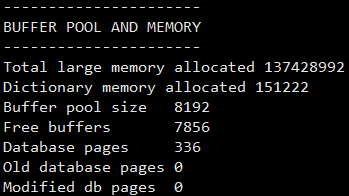
注:show engine innodb status命令顯示的不是最新的狀態(tài),而是過(guò)去某個(gè)時(shí)間范圍的狀態(tài),可以從命令前面返回的文本看到
緩沖池緩存的數(shù)據(jù)頁(yè)類型有:索引頁(yè)、數(shù)據(jù)頁(yè)、undo頁(yè)、插入緩沖、自適應(yīng)哈希索引、InnoDB存儲(chǔ)的鎖信息、數(shù)據(jù)字典信息等
如上圖,日志緩沖將重做日志信息放入緩沖區(qū),然后按照一定的頻率刷新到日志文件,只需要保證每秒產(chǎn)生的事務(wù)量在這個(gè)緩沖區(qū)之內(nèi)就可以
額外內(nèi)存池的值設(shè)定也很重要,InnoDB中內(nèi)存是堆的管理方式,在對(duì)一些數(shù)據(jù)結(jié)構(gòu)本身分配內(nèi)存時(shí),需要從額外的內(nèi)存池申請(qǐng),當(dāng)該區(qū)域不夠時(shí),會(huì)從緩沖區(qū)申請(qǐng)。InnoDB實(shí)例會(huì)申請(qǐng)緩沖池空間,但每個(gè)緩沖池的幀緩沖還有緩沖控制對(duì)象,這些對(duì)象記錄了如LRU、鎖、等待等方面的信息,對(duì)象的內(nèi)存需要從額外的內(nèi)存池中申請(qǐng),當(dāng)申請(qǐng)了很大的InnoDB緩沖池時(shí),應(yīng)釋放增加額外內(nèi)存池的空間
3.3 master thread
master thread線程的優(yōu)先級(jí)是最高的,內(nèi)部由幾個(gè)循環(huán)組成,主循環(huán)(loop),后臺(tái)循環(huán)(background loop),刷新循環(huán)(flush loop),master thread的狀態(tài)在loop、background loop、flush loop和 suspend loop中切換
-
loop:主循環(huán),通過(guò)thread sleep實(shí)現(xiàn)
-
每秒的操作
-
日志緩沖刷新到磁盤,即使事務(wù)沒(méi)有提交(總是執(zhí)行)
-
合并插入緩沖(可能執(zhí)行)io<5
-
最多100個(gè)InnoDB的緩沖池中的臟頁(yè)到磁盤(可能執(zhí)行)dirty_pages判斷閾值>90%
-
如果當(dāng)前沒(méi)有用戶活動(dòng),切換到后臺(tái)循環(huán)(可能執(zhí)行)
-
-
每10秒的操作
-
刷新100個(gè)臟頁(yè)到磁盤(可能執(zhí)行)io<200
-
合并至多5個(gè)插入緩沖(總是執(zhí)行)
-
將日志緩沖刷新到磁盤(總是執(zhí)行)
-
刪除無(wú)用的Undo頁(yè)(總是執(zhí)行)
-
刷新100個(gè)或者10個(gè)臟頁(yè)到磁盤(總是執(zhí)行)
-
產(chǎn)生一個(gè)檢查點(diǎn)(總是執(zhí)行)
-
-
-
background loop:后臺(tái)循環(huán),當(dāng)沒(méi)有用戶活動(dòng)或數(shù)據(jù)庫(kù)關(guān)閉時(shí),會(huì)切換到這個(gè)循環(huán)
- 執(zhí)行操作
- 刪除無(wú)用的redo頁(yè)(總是執(zhí)行)
- 合并20個(gè)插入緩沖(總是執(zhí)行)
- 跳回到主循環(huán)(總是執(zhí)行)
- 不斷刷新100個(gè)頁(yè),直到符合條件(可能執(zhí)行,跳轉(zhuǎn)到flush loop完成)
- 執(zhí)行操作
-
flush loop:刷新循環(huán)
- 執(zhí)行操作
- 。。。
- 切換至suspend_loop,將master thread掛起,等待事件發(fā)生
- 執(zhí)行操作
問(wèn)題:上述的master線程調(diào)度方式存在一定的弊端,尤其是在固態(tài)硬盤出現(xiàn)后,極大地影響了磁盤的IO性能,特別是寫入性能。因?yàn)闊o(wú)論何時(shí),InnoDB引擎最多才會(huì)刷新100個(gè)臟頁(yè)到磁盤,合并20個(gè)插入緩沖,在密集型應(yīng)用程序中,每秒產(chǎn)生的臟頁(yè)或插入緩沖遠(yuǎn)大于預(yù)估值,此時(shí)master thread將會(huì)出現(xiàn)性能瓶頸,發(fā)生宕機(jī)需要恢復(fù)時(shí),很多數(shù)據(jù)未刷新會(huì)磁盤,導(dǎo)致恢復(fù)需要很長(zhǎng)時(shí)間
對(duì)策:發(fā)布修正補(bǔ)丁,動(dòng)態(tài)修改插入緩沖的百分比與刷新臟頁(yè)的數(shù)量,以及其他參數(shù)
3.4 關(guān)鍵特性
一些關(guān)鍵特性:插入緩沖、兩次寫、自適應(yīng)哈希索引,這些特性帶來(lái)了更好的性能與更高的可靠性
3.4.1 插入緩沖
緣由:只存在一個(gè)聚集索引的情況下,插入語(yǔ)句執(zhí)行會(huì)很快,但是存在多個(gè)非聚集索引的情況,葉子節(jié)點(diǎn)的插入順序不再是順序執(zhí)行,由于B+樹的特性,插入新功能變低了
解決方案:提出插入緩沖概念,對(duì)于非聚集索引的插入或更新操作,先判斷非聚集索引頁(yè)是否在緩沖池中,在則插入,否則先放入緩沖池,騙過(guò)數(shù)據(jù)庫(kù)這個(gè)索引已經(jīng)插到葉子節(jié)點(diǎn)了,然后以一定的頻率執(zhí)行插入緩沖和非聚集索引葉子節(jié)點(diǎn)合并操作,此時(shí)將多個(gè)插入操作合并到一個(gè)操作中,提高了性能
需滿足兩個(gè)條件:① 索引是輔助索引;② 索引不是唯一的
3.4.2 兩次寫
場(chǎng)景:數(shù)據(jù)庫(kù)宕機(jī)時(shí)且正在寫入頁(yè)面未完成,稱為部分寫失效,因重做日志記錄的是對(duì)頁(yè)的物理操作,頁(yè)本身已經(jīng)損壞,無(wú)法進(jìn)行重做,因此需要一個(gè)頁(yè)的副本,寫入失效發(fā)生時(shí),通過(guò)頁(yè)的副本還原該頁(yè),就是doublewrite
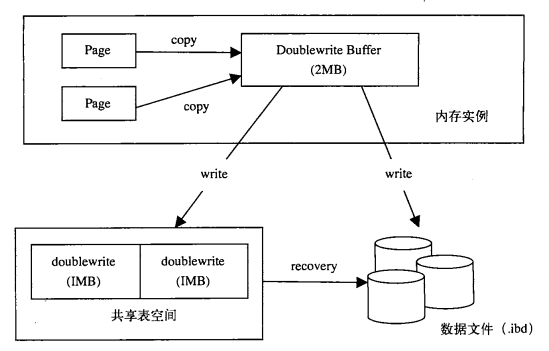
解決方案:doublewrite由兩部分組成,一部分是內(nèi)存中的doublewrite buffer,另一部分是物理磁盤共享表空間的連續(xù)128個(gè)頁(yè),大小均為2MB。
當(dāng)緩沖池的臟頁(yè)刷新時(shí),不會(huì)直接寫入磁盤,而會(huì)通過(guò)mencpy函數(shù)將臟頁(yè)拷貝到內(nèi)存中的doublewrite buffer,doublewrite buffer會(huì)分兩次寫入共享表空間的物理磁盤,隨后即刻調(diào)用fsync函數(shù)同步到磁盤文件
3.4.3 自適應(yīng)哈希索引
簡(jiǎn)介:
InnoDB會(huì)監(jiān)控對(duì)表上索引的查找,如果觀察到建立哈希索引可以帶來(lái)速度提升,則會(huì)建立,稱之自適應(yīng)。自適應(yīng)哈希索引是根據(jù)緩沖池的B+樹構(gòu)造而來(lái)的,建立速度很快,而無(wú)需將整個(gè)表建立索引,InnoDB會(huì)自動(dòng)根據(jù)訪問(wèn)頻率和模式為某些頁(yè)建立哈希索引
定義:
InnoDB存儲(chǔ)引擎會(huì)監(jiān)控對(duì)表上各索引頁(yè)的查詢。并建立合適的哈希索引,加速數(shù)據(jù)頁(yè)的訪問(wèn)
特點(diǎn):
- 查詢消耗O(1)
- 降低二級(jí)索引樹的頻繁訪問(wèn)資源
- 自適應(yīng)
劣勢(shì):
- hash自適應(yīng)索引會(huì)占用innodb buffer pool
- 自適應(yīng)hash索引只適合搜索等值的查詢,如select * from table where index_col=‘xxx’,而對(duì)于其他查找類型,如范圍查找,是不能使用的
自適應(yīng)散列索引(AHI)使InnoDB在系統(tǒng)上執(zhí)行更像內(nèi)存數(shù)據(jù)庫(kù),該功能由innodb_adaptive_hash_index 配置啟用
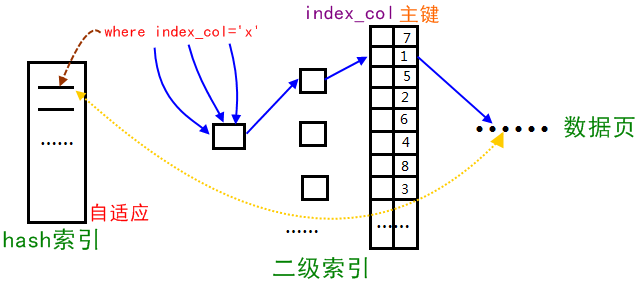
InnoDB存儲(chǔ)引擎會(huì)監(jiān)控對(duì)表上二級(jí)索引的查找,如果發(fā)現(xiàn)某二級(jí)索引被頻繁訪問(wèn),InnoDB就會(huì)使用索引鍵的前綴建立一個(gè)哈希索引。將索引值轉(zhuǎn)換為一種指針,便于直接訪問(wèn),帶來(lái)速度的提升
經(jīng)常訪問(wèn)的二級(jí)索引數(shù)據(jù)會(huì)自動(dòng)被生成到hash索引里面去(最近連續(xù)被訪問(wèn)三次的數(shù)據(jù)),自適應(yīng)哈希索引通過(guò)緩沖池的B+樹構(gòu)造而來(lái),因此建立的速度很快
3.5 啟動(dòng)、關(guān)閉與恢復(fù)
參數(shù)innodb_fast_shutdown說(shuō)明:
取值0:表示關(guān)閉時(shí)需完成所有的full purge和merge insert buffer操作,需花費(fèi)較長(zhǎng)時(shí)間
取值1:默認(rèn)值,無(wú)需完成上述的full purge和merge insert buffer操作,但緩沖池的數(shù)據(jù)臟頁(yè)仍會(huì)刷新到磁盤
取值2:僅將日志寫入日志文件,在下次啟動(dòng)時(shí)會(huì)執(zhí)行恢復(fù)操作
參數(shù)innodb_force_recovery說(shuō)明:默認(rèn)為0,表示需要恢復(fù)時(shí)執(zhí)行所有的恢復(fù)操作。當(dāng)不能有效恢復(fù)時(shí),如數(shù)據(jù)頁(yè)發(fā)生了corruption日志,數(shù)據(jù)庫(kù)可能會(huì)宕機(jī),并把錯(cuò)誤寫入錯(cuò)誤日志
取值1:忽略檢查到的corruption頁(yè)
取值2:阻止主線程的運(yùn)行,如主線程需要執(zhí)行full purge操作,會(huì)導(dǎo)致crash
取值3:不執(zhí)行事務(wù)回滾操作
取值4:不執(zhí)行插入緩沖的合并操作
取值5:不查看撤銷日志,innoDB會(huì)將未提交的事務(wù)視為已提交
取值6:不執(zhí)行前滾的操作
注:設(shè)置了該值大于0后,可以對(duì)表進(jìn)行select、create、drop操作,但是insert、update和delete操作是不被允許的
4 InnoDB內(nèi)部詳解
4.1 文件
4.1.1 參數(shù)文件 my.cnf
指定啟動(dòng)初始化參數(shù)
-
動(dòng)態(tài)參數(shù):可在MySQL實(shí)例運(yùn)行中更改
-
靜態(tài)參數(shù):在實(shí)例生命周期內(nèi)不得更改
-
日志文件
-
錯(cuò)誤日志:記錄啟動(dòng)、運(yùn)行、關(guān)閉的過(guò)程,以及警告和錯(cuò)誤等錯(cuò)誤信息
-
慢查詢?nèi)罩荆涸O(shè)定一個(gè)閾值,將超過(guò)閾值的查詢SQL語(yǔ)句記錄到慢查詢?nèi)罩疚募?/p>
-
查詢?nèi)罩荆河涗浟怂袑?duì)數(shù)據(jù)庫(kù)的請(qǐng)求,可以將日志的記錄存放在mysql下的general_log表
-
二進(jìn)制日志(binlog):不包含select、show等操作,記錄執(zhí)行數(shù)據(jù)庫(kù)更改操作的時(shí)間和執(zhí)行時(shí)間等信息
-
恢復(fù):數(shù)據(jù)恢復(fù)需要二進(jìn)制文件,當(dāng)一個(gè)數(shù)據(jù)庫(kù)全備文件恢復(fù)后,可通過(guò)二進(jìn)制日志進(jìn)行point-in-time的恢復(fù)
-
復(fù)制:通過(guò)復(fù)制和執(zhí)行二進(jìn)制日志文件可以使兩臺(tái)MySQL服務(wù)器進(jìn)行實(shí)時(shí)同步
-
binlog_format參數(shù):
-
STATEMENT:記錄日志的邏輯SQL語(yǔ)句
-
ROW(默認(rèn)):記錄表的行更改情況,一般搭配事務(wù)隔離級(jí)別READ COMMITTED
-
MIXED:該格式默認(rèn)采用STATEMENT格式記錄二進(jìn)制日志,但在一些情況下使用ROW格式:
- 表存儲(chǔ)引擎是NDB,進(jìn)行的DML操作會(huì)以ROW記錄
- 使用UUID() USER() CURRENT_USER() FOUND_ROWS() ROW_COUNT() 等不確定函數(shù)
- 使用INSERT DELAY語(yǔ)句
- 使用用戶定義函數(shù)(UDF)
- 使用臨時(shí)表

-
-
-

4.1.2 套接字文件socket
用于本地套接字方式連接

4.1.3 pid文件
記錄進(jìn)程id

4.1.4 表結(jié)構(gòu)定義frm文件
存放MySQL表結(jié)構(gòu)定義,存放在data目錄下的每個(gè)獨(dú)立數(shù)據(jù)庫(kù)文件夾中
4.1.5 InnoDB存儲(chǔ)引擎文件
-
表空間文件:ibdata1 ibdata2
由于是InnoDB存儲(chǔ)引擎,且設(shè)置了innodb_file_per_table=ON,產(chǎn)生了單獨(dú)的.ibd表空間,這些單獨(dú)二表空間僅存儲(chǔ)該表的數(shù)據(jù)、索引和插入緩沖等信息,其余數(shù)據(jù)還是存放在默認(rèn)的表空間中
-
重做日志文件:ib_logfile1 ib_logfile2,也稱redo log file,記錄了對(duì)于InnoDB存儲(chǔ)引擎的事務(wù)日志
作用:由于主機(jī)掉電導(dǎo)致實(shí)例失敗,InnoDB會(huì)重做日志恢復(fù)到掉電前的時(shí)刻,確保數(shù)據(jù)的完整性。
每個(gè)InnoDB存儲(chǔ)引擎至少有一個(gè)重做日志文件組,每組至少有2個(gè)重做日志文件,如ib_logfile0、ib_logfile1。
為確保可用性,可設(shè)置多個(gè)鏡像日志組,將不同的文件組放在不同的磁盤上,每個(gè)重做日志大小一致,并循環(huán)使用
重做日志寫入:先寫入日志緩沖,根據(jù)innodb_flush_log_at_trx_commit參數(shù)控制在commit時(shí)處理操作日志的方式,0表示不將重做日志寫入磁盤的日志文件,而是等待主線程每秒的刷新;1表示在commit時(shí)將重做日志緩沖寫入磁盤,而2表示異步寫入,不能保證commit時(shí)一定會(huì)寫入重做日志文件
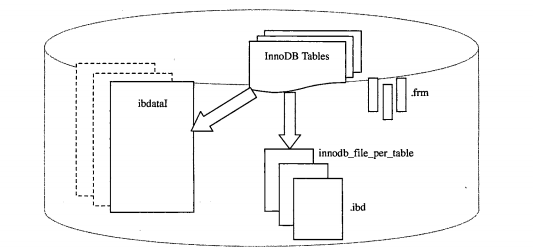
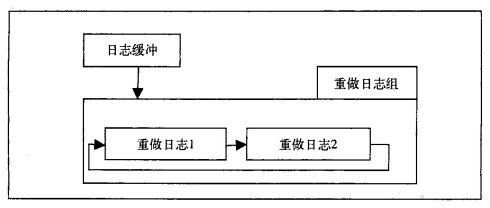
4.2 表
InnoDB規(guī)定每張表都需要定義主鍵,如果存在非空唯一索引則自動(dòng)設(shè)為主鍵,否則InnoDB自動(dòng)創(chuàng)建一個(gè)6個(gè)字節(jié)大小的指針作為主鍵
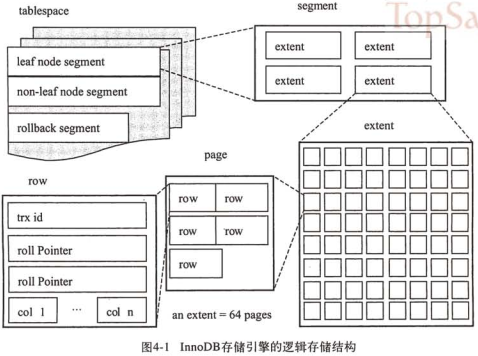
InnoDB邏輯存儲(chǔ)結(jié)構(gòu):
表空間(tablespace):位于InnoDB存儲(chǔ)邏輯的最高層,存放所有數(shù)據(jù)。默認(rèn)共享表空間ibdata1,若指定innodb_file_per_table則每張表的數(shù)據(jù)被單獨(dú)放在一個(gè)表空間中
-
段(segment):
表空間由段組成,常見(jiàn)數(shù)據(jù)段、索引段、回滾段等
InnoDB存儲(chǔ)索引表是索引組織的,數(shù)據(jù)即索引,索引即數(shù)據(jù),數(shù)據(jù)段為B+樹的葉子節(jié)點(diǎn),索引段即B+樹的非葉子節(jié)點(diǎn)
-
區(qū)(extent):
由64個(gè)連續(xù)的頁(yè)組成,每個(gè)頁(yè)大小16KB,每個(gè)區(qū)大小1MB。每個(gè)數(shù)據(jù)段至多申請(qǐng)4個(gè)區(qū),以保證數(shù)據(jù)的順序性能
每個(gè)段開(kāi)始時(shí),有32個(gè)頁(yè)大小的碎片頁(yè)存放數(shù)據(jù),使用完再進(jìn)行64個(gè)連續(xù)頁(yè)的申請(qǐng)
#page info Total number of page: 6 #總頁(yè)數(shù) Freshly Allocated Page: 2 #可用頁(yè) Insert Buffer Bitmap: 1 #插入緩存位圖頁(yè) File Space Header: 1 #插入緩存空閑列表頁(yè) B-tree Node: 1 #數(shù)據(jù)頁(yè) File Segment inode: 1 #二進(jìn)制大對(duì)象頁(yè),存放溢出行的頁(yè),即溢出頁(yè)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
初始大小:16kb * 6(頁(yè)的總數(shù)量) = 96kb
-
頁(yè)(page):
頁(yè)是磁盤管理的最小單位,默認(rèn)頁(yè)大小16KB,不可更改
常見(jiàn)頁(yè)類型:
- 數(shù)據(jù)頁(yè)
- Undo頁(yè)
- 系統(tǒng)頁(yè)
- 事務(wù)處理頁(yè)
- 插入緩沖位圖頁(yè)
- 插入緩沖空閑列表頁(yè)
- 未壓縮的二進(jìn)制大對(duì)象頁(yè)
- 壓縮的二進(jìn)制大對(duì)象頁(yè)
-
行
InnoDB存儲(chǔ)引擎是面向行的,每頁(yè)最多存放16KB/2-200(頁(yè)保留)行的記錄,即7992行記錄
InnoDB物理存儲(chǔ)結(jié)構(gòu):
組成:共享表空間、日志文件(redo)組、表結(jié)構(gòu)定義文件
.ibd:獨(dú)立表空間文件
.frm:表結(jié)構(gòu)定義文件,與存儲(chǔ)引擎無(wú)關(guān)
InnoDB行記錄格式:
-
Compact行記錄格式:
-
變長(zhǎng)字段長(zhǎng)度列表:逆序存放,列長(zhǎng)度小于255字節(jié),用1字節(jié)表示,否則使用2字節(jié)表示,因此varchar最大長(zhǎng)度是65535
-
null標(biāo)志位:表示該行數(shù)據(jù)中是否有null值,用1表示
-
記錄頭信息:固定占用5字節(jié)
-
實(shí)際存儲(chǔ)的列數(shù)據(jù):
null不占用該部分?jǐn)?shù)據(jù),只占有標(biāo)志位。
此外還有兩個(gè)隱藏列,事務(wù)id和回滾指針列,分別為6個(gè)字節(jié)和7個(gè)字節(jié)的大小,若未定義主鍵,還會(huì)增加一個(gè)6字節(jié)的RowID列
后面的列數(shù)據(jù)的就是數(shù)據(jù)表的實(shí)際列數(shù)目
-
-
Redundant行記錄格式:MySQL5.0之前的行存儲(chǔ)方式
-
字段長(zhǎng)度偏移列表:按照列順序逆序放置,列長(zhǎng)度小于255字節(jié),用1字節(jié)表示;若大于用2字節(jié)表示
-
記錄頭信息:固定占用6字節(jié)
-
列數(shù)據(jù):varchar的null值不占用空間,而char的null值會(huì)占用空間,而在compact中是完全不占用空間的
-
-
行溢出數(shù)據(jù):
varchar類型原則上可存放65535長(zhǎng)度數(shù)據(jù),實(shí)際最多存放65532長(zhǎng)度數(shù)據(jù)
-
Compressed和Dynamic行記錄格式:采用了完全的行溢出方式,在數(shù)據(jù)頁(yè)存放20個(gè)字節(jié)的指針,實(shí)際數(shù)據(jù)存放在BLOB Page中
Compressed存儲(chǔ)的行數(shù)據(jù)使用zlib算法進(jìn)行壓縮,針對(duì)BLOB、TEST、VARCHAR這類長(zhǎng)數(shù)據(jù)類型得到有效的壓縮
-
Char的行結(jié)構(gòu)存儲(chǔ)
CHAR(N) N表示的是字符的長(zhǎng)度,而不是之前版本字節(jié)長(zhǎng)度,不同字符集下,CHAR內(nèi)部存儲(chǔ)的不是定長(zhǎng)的數(shù)據(jù)





InnoDB數(shù)據(jù)頁(yè)格式:
頁(yè)是InnoDB存儲(chǔ)引擎管理數(shù)據(jù)庫(kù)的最小單位,頁(yè)類型是B+樹的頁(yè),存放具體的行數(shù)據(jù)
組成:
- File Header 文件頭
- Page Header 頁(yè)頭
- Infimun + Supermum Records
- User Records 用戶記錄
- Free Space 空閑空間
- Page Directory 頁(yè)目錄
- File Trailer 文件結(jié)尾信息
Named File Formats:
為解決新的頁(yè)數(shù)據(jù)結(jié)構(gòu)與之前版本的頁(yè)不兼容的問(wèn)題,從InnoDB Plugin版本開(kāi)始,InnoDB存儲(chǔ)引擎引入Named FileFormats機(jī)制解決不同版本頁(yè)結(jié)構(gòu)的兼容性問(wèn)題
InnoDB將之前版本的文件格式定義為Antelope,將當(dāng)前版本文件格式定義為Barracuda。Antelope文件格式有Compact和Redudant的行格式,Barracuda文件格式支持Antelope所有格式,此外也新加入了Compossed和Dynamic行記錄格式
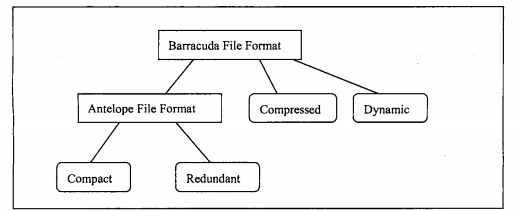
約束:
數(shù)據(jù)完整性三種形式
- 實(shí)體完整性:通過(guò)定義primary key和unique key約束來(lái)保證實(shí)體完整性
- 域完整性:保證數(shù)據(jù)的值滿足特定的條件
- 參照完整性:保證表之間的關(guān)系,InnoDB支持外鍵,允許用戶自定義外鍵
InnoDB存儲(chǔ)引擎幾種約束:
- Primary Key
- Unique Key
- Foreign Key
- Default
- NOT NULL
視圖:
是一個(gè)命名的虛表,由一個(gè)查詢來(lái)定義,視圖的數(shù)據(jù)無(wú)物理表現(xiàn)形式
分區(qū)表:
從MySQL5.1版本之后支持分區(qū),將一個(gè)表或索引分解成多個(gè)更小、更加可管理的部分。一個(gè)邏輯表由多個(gè)物理分區(qū)組成,每個(gè)分區(qū)都是一個(gè)獨(dú)立對(duì)象
MySQL支持的分區(qū)類型是水平分區(qū),不支持垂直分區(qū),數(shù)據(jù)庫(kù)分區(qū)是局部分區(qū)索引,一個(gè)分區(qū)既存放數(shù)據(jù)也存放索引
支持的分區(qū)類型:
- RANGE分區(qū):行數(shù)據(jù)基于一個(gè)定連續(xù)區(qū)間的列值放入空間
- LIST分區(qū):LIST分區(qū)面向的是離散的值
- HASH分區(qū):根據(jù)用戶自定義的表達(dá)式返回值進(jìn)行分區(qū),返回值不為負(fù)數(shù)
- KEY分區(qū):根據(jù)MySQL提供的哈希函數(shù)進(jìn)行分區(qū)
RANGE分區(qū):
使用range分區(qū)表時(shí),表上的物理文件不再是由一個(gè)ibd文件組成了,而是由建立分區(qū)的各個(gè)分區(qū)ibd文件組成

當(dāng)插入一個(gè)不在分區(qū)范圍的值時(shí),MySQL將拋出異常,可通過(guò)添加一個(gè)MAXVALUE值的分區(qū),可理解為正無(wú)窮

LIST分區(qū):
區(qū)別于RANGE分區(qū),LIST分區(qū)的值是離散的

HASH分區(qū):
將數(shù)據(jù)均勻的分布到預(yù)定義的各個(gè)分區(qū)中,保證各分區(qū)數(shù)量大致都是一樣的,大多數(shù)工作MySQL將自動(dòng)完成,僅需將要被哈希的列值指定一個(gè)列值或表達(dá)式,以及需要分割的數(shù)量,默認(rèn)1

MySQL還支持一種線性哈希的分區(qū),使用更加復(fù)雜的算法確定新行插入分區(qū)表的位置,語(yǔ)法與hash類似


優(yōu)勢(shì)在于增加、刪除、合并和拆分分區(qū)將變得更加快捷,有利于處理大量數(shù)據(jù)的表,缺點(diǎn)是相較于HASH分區(qū)得到的數(shù)據(jù),各分區(qū)分布可能不太均衡
KEY分區(qū):
與HASH分區(qū)類型,不同的是,KEY分區(qū)使用MySQL數(shù)據(jù)庫(kù)提供的函數(shù)進(jìn)行分區(qū)

在KEY分區(qū)使用LINEAR參數(shù),等同于HASH分區(qū),分區(qū)編號(hào)通過(guò)2的冪算法得到的
COLUMNS分區(qū):
其他分區(qū)都需要分區(qū)條件為整型,而COLUMNS分區(qū)可以直接使用非整型的數(shù)據(jù)進(jìn)行分區(qū),分區(qū)根據(jù)類型直接比較而得,無(wú)需進(jìn)行轉(zhuǎn)化,其次,可以對(duì)多個(gè)值進(jìn)行分區(qū)
支持的數(shù)據(jù)類型:
- 所有的整數(shù)類型:INT、SMALLINT、TINYINT、BIGINT,不支持FLOAT和 DECIMAL
- 日期類型:DATE和DATETIME
- 字符串類型:CHAR、VARCHAR、BINARY、VARBINARY
子分區(qū):
在分區(qū)的基礎(chǔ)上繼續(xù)分區(qū),也成為復(fù)合分區(qū),MySQL支持在RANGE和LIST分區(qū)上再進(jìn)行HASH或者是KEY的子分區(qū)
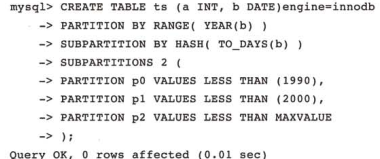
注:分區(qū)并不總適用于OLTP應(yīng)用,應(yīng)根據(jù)應(yīng)用類型規(guī)劃分區(qū)設(shè)計(jì)
4.3 索引與算法
幾種二叉樹的概念:
二叉查找樹:
特點(diǎn)不平衡,在二叉樹的基礎(chǔ)上需要滿足:任意節(jié)點(diǎn)的左子樹上所有節(jié)點(diǎn)值不大于根節(jié)點(diǎn)的值,任意節(jié)點(diǎn)的右子樹上所有節(jié)點(diǎn)值不小于根節(jié)點(diǎn)的值
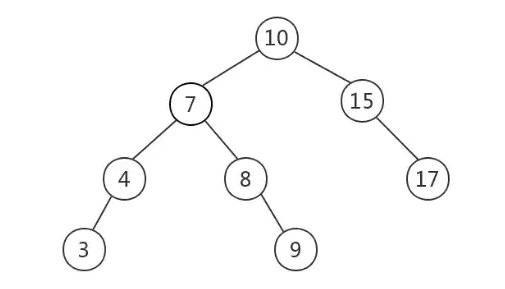
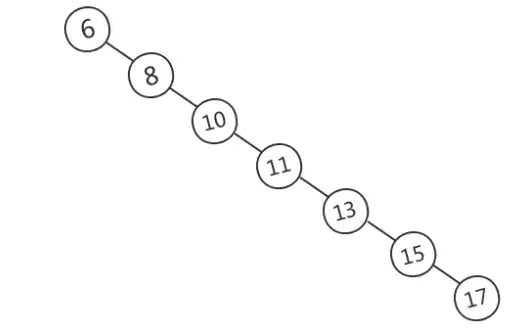
當(dāng)需要快速查找時(shí),將數(shù)據(jù)存儲(chǔ)在BST是一種常見(jiàn)的選擇,因?yàn)榇藭r(shí)查詢時(shí)間取決于樹高,平均時(shí)間復(fù)雜度是O(lgn)。然而,BST可能長(zhǎng)歪而變得不平衡,如下圖所示,此時(shí)BST退化為鏈表,時(shí)間復(fù)雜度退化為O(n)
平衡二叉樹(AVL):
AVL樹是嚴(yán)格的平衡二叉樹,所有節(jié)點(diǎn)的左右子樹高度差不能超過(guò)1;AVL樹查找、插入和刪除在平均和最壞情況下都是O(lgn)
AVL實(shí)現(xiàn)平衡的關(guān)鍵在于旋轉(zhuǎn)操作:插入和刪除可能破壞二叉樹的平衡,此時(shí)需要通過(guò)一次或多次樹旋轉(zhuǎn)來(lái)重新平衡這個(gè)樹。當(dāng)插入數(shù)據(jù)時(shí),最多只需要1次旋轉(zhuǎn)(單旋轉(zhuǎn)或雙旋轉(zhuǎn));但是當(dāng)刪除數(shù)據(jù)時(shí),會(huì)導(dǎo)致樹失衡,AVL需要維護(hù)從被刪除節(jié)點(diǎn)到根節(jié)點(diǎn)這條路徑上所有節(jié)點(diǎn)的平衡,旋轉(zhuǎn)的量級(jí)為O(lgn)
由于旋轉(zhuǎn)的耗時(shí),AVL樹在刪除數(shù)據(jù)時(shí)效率很低;在刪除操作較多時(shí),維護(hù)平衡所需的代價(jià)可能高于其帶來(lái)的好處,因此AVL實(shí)際使用并不廣泛
紅黑樹:
與AVL樹相比,紅黑樹并不追求嚴(yán)格的平衡,而是大致的平衡:只是確保從根到葉子的最長(zhǎng)的可能路徑不多于最短的可能路徑的兩倍長(zhǎng)。從實(shí)現(xiàn)來(lái)看,紅黑樹最大的特點(diǎn)是每個(gè)節(jié)點(diǎn)都屬于兩種顏色(紅色或黑色)之一,且節(jié)點(diǎn)顏色的劃分需要滿足特定的規(guī)則(具體規(guī)則略)
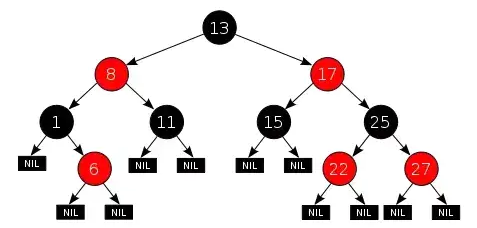
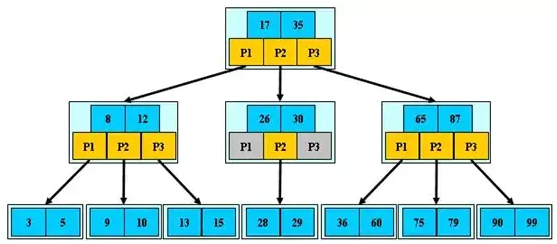
B樹:
B樹也稱B-樹(其中不是減號(hào)),是為磁盤等輔存設(shè)備設(shè)計(jì)的多路平衡查找樹,與二叉樹相比,樹的每個(gè)非葉節(jié)點(diǎn)可以有多個(gè)子樹
定義B樹最重要的概念是階數(shù)(Order),對(duì)于一顆m階B樹,需要滿足以下條件:
- 每個(gè)節(jié)點(diǎn)最多包含 m 個(gè)子節(jié)點(diǎn)。
- 如果根節(jié)點(diǎn)包含子節(jié)點(diǎn),則至少包含 2 個(gè)子節(jié)點(diǎn);除根節(jié)點(diǎn)外,每個(gè)非葉節(jié)點(diǎn)至少包含 m/2 個(gè)子節(jié)點(diǎn)。
- 擁有 k 個(gè)子節(jié)點(diǎn)的非葉節(jié)點(diǎn)將包含 k - 1 條記錄。
- 所有葉節(jié)點(diǎn)都在同一層中。
B樹的優(yōu)勢(shì)除了樹高小,還有對(duì)訪問(wèn)局部性原理的利用。所謂局部性原理,是指當(dāng)一個(gè)數(shù)據(jù)被使用時(shí),其附近的數(shù)據(jù)有較大概率在短時(shí)間內(nèi)被使用。B樹將鍵相近的數(shù)據(jù)存儲(chǔ)在同一個(gè)節(jié)點(diǎn),當(dāng)訪問(wèn)其中某個(gè)數(shù)據(jù)時(shí),數(shù)據(jù)庫(kù)會(huì)將該整個(gè)節(jié)點(diǎn)讀到緩存中;當(dāng)它臨近的數(shù)據(jù)緊接著被訪問(wèn)時(shí),可以直接在緩存中讀取,無(wú)需進(jìn)行磁盤IO;換句話說(shuō),B樹的緩存命中率更高
B+樹:
與B樹的區(qū)別:
-
B樹中每個(gè)節(jié)點(diǎn)(包括葉節(jié)點(diǎn)和非葉節(jié)點(diǎn))都存儲(chǔ)真實(shí)的數(shù)據(jù),B+樹中只有葉子節(jié)點(diǎn)存儲(chǔ)真實(shí)的數(shù)據(jù),非葉節(jié)點(diǎn)只存儲(chǔ)鍵。在MySQL中,這里所說(shuō)的真實(shí)數(shù)據(jù),可能是行的全部數(shù)據(jù)(如Innodb的聚簇索引),也可能只行的主鍵(如Innodb的輔助索引),或者是行所在的地址(如MyIsam的非聚簇索引)
-
B樹中一條記錄只會(huì)出現(xiàn)一次,不會(huì)重復(fù)出現(xiàn),而B+樹的鍵則可能重復(fù)重現(xiàn)——一定會(huì)在葉節(jié)點(diǎn)出現(xiàn),也可能在非葉節(jié)點(diǎn)重復(fù)出現(xiàn)。
-
B+樹的葉節(jié)點(diǎn)之間通過(guò)雙向鏈表鏈接
-
B樹中的非葉節(jié)點(diǎn),記錄數(shù)比子節(jié)點(diǎn)個(gè)數(shù)少1;而B+樹中記錄數(shù)與子節(jié)點(diǎn)個(gè)數(shù)相同
具有以下優(yōu)勢(shì):
- 更少的IO次數(shù): B+樹的非葉節(jié)點(diǎn)只包含鍵,而不包含真實(shí)數(shù)據(jù),因此每個(gè)節(jié)點(diǎn)存儲(chǔ)的記錄個(gè)數(shù)比B數(shù)多很多(即階m更大),因此B+樹的高度更低,訪問(wèn)時(shí)所需要的IO次數(shù)更少。此外,由于每個(gè)節(jié)點(diǎn)存儲(chǔ)的記錄數(shù)更多,所以對(duì)訪問(wèn)局部性原理的利用更好,緩存命中率更高
- 更適于范圍查詢: 在B樹中進(jìn)行范圍查詢時(shí),首先找到要查找的下限,然后對(duì)B樹進(jìn)行中序遍歷,直到找到查找的上限;而B+樹的范圍查詢,只需要對(duì)鏈表進(jìn)行遍歷即可
- 更穩(wěn)定的查詢效率: B樹的查詢時(shí)間復(fù)雜度在1到樹高之間(分別對(duì)應(yīng)記錄在根節(jié)點(diǎn)和葉節(jié)點(diǎn)),而B+樹的查詢復(fù)雜度則穩(wěn)定為樹高,因?yàn)樗袛?shù)據(jù)都在葉節(jié)點(diǎn)
B+樹也存在劣勢(shì):由于鍵會(huì)重復(fù)出現(xiàn),因此會(huì)占用更多的空間。但是與帶來(lái)的性能優(yōu)勢(shì)相比,空間劣勢(shì)往往可以接受,因此B+樹的在數(shù)據(jù)庫(kù)中的使用比B樹更加廣泛
B+樹的兩種索引形式:
-
聚集索引(主鍵索引)
InnoDB存儲(chǔ)引擎是索引組織表,表中的數(shù)據(jù)按照逐漸的順序存放,聚集索引就是將,每個(gè)表的主鍵構(gòu)造一棵B+樹,且葉子節(jié)點(diǎn)存放的是表的行記錄數(shù)據(jù),因此聚集索引的葉子節(jié)點(diǎn)成為數(shù)據(jù)頁(yè),每個(gè)數(shù)據(jù)頁(yè)通過(guò)一個(gè)雙線鏈表進(jìn)行鏈接
實(shí)際的數(shù)據(jù)頁(yè)只能按照一顆B+樹進(jìn)行排序,因此每張表只有一個(gè)聚集索引。查詢優(yōu)化器傾向于聚集索引,能夠在索引的葉子節(jié)點(diǎn)找到數(shù)據(jù)
-
輔助聚集索引
葉子節(jié)點(diǎn)不包含行的全部數(shù)據(jù),除了包含鍵值外,每個(gè)頁(yè)級(jí)別的索引行包含一個(gè)書簽,用于高速存儲(chǔ)引擎哪里可以找到與索引相關(guān)的行數(shù)據(jù),因此輔助索引的書簽就是相應(yīng)行的聚集索引鍵
添加/刪除B+樹索引:
-
ALTER TABLE
-
CREATE / DROP INDEX
MySQL的InnoDB存儲(chǔ)引擎使用S鎖解決添加刪除索引時(shí)需要?jiǎng)?chuàng)建臨時(shí)表與數(shù)據(jù)導(dǎo)入同步的過(guò)程,但僅限于輔助索引,對(duì)于主鍵索引不適用
B+樹索引的使用原則:高選擇,取表中少部分?jǐn)?shù)據(jù)
哈希算法:
- 哈希表
- InnoDB哈希算法
? InnoDB哈希函數(shù):除法散列
? 哈希沖突解決機(jī)制:鏈表
? 散列算法:K = space(表空間號(hào)) << 20 + space + offset(偏移量)
-
自適應(yīng)哈希索引
InnoDB存儲(chǔ)引擎會(huì)監(jiān)控對(duì)表上二級(jí)索引的查找,如果發(fā)現(xiàn)某二級(jí)索引被頻繁訪問(wèn),二級(jí)索引成為熱數(shù)據(jù),建立哈希索引可以帶來(lái)速度的提升
附錄
MySQL日志類型
- 錯(cuò)誤日志:服務(wù)運(yùn)行過(guò)程中發(fā)生的嚴(yán)重錯(cuò)誤日志
- 二進(jìn)制日志:也叫Binlog,其記錄了對(duì)數(shù)據(jù)庫(kù)所有的更改
- 查詢?nèi)罩荆河涗浟藖?lái)自客戶端的所有語(yǔ)句
- 慢查詢?nèi)罩荆哼@里記錄了所有響應(yīng)時(shí)間超過(guò)閾值的SQL語(yǔ)句,這個(gè)閾值我們可以自己設(shè)置,參數(shù)為
long_query_time,其默認(rèn)值為10s,且默認(rèn)是關(guān)閉的狀態(tài),需要手動(dòng)打開(kāi)
MySQL中的Binlog日志是重要日志,可以給其他類型存儲(chǔ)引擎使用,記錄了所有對(duì)數(shù)據(jù)庫(kù)的修改
-
statement:記錄所有會(huì)修改數(shù)據(jù)的SQL,只記錄sql,不記錄SQL影響的所有行,減少了日志數(shù)量
-
row:只保存被修改的記錄,會(huì)存在大量的日志
-
mixedlevel:屬于statement與row的混用
InnoDB的中兩個(gè)重要日志:
-
Redo log:重做日志,記錄事務(wù)操作后的值,無(wú)論事務(wù)是否提交。更新數(shù)據(jù)時(shí),會(huì)將更新記錄寫到redo log中,再更新緩存頁(yè)的數(shù)據(jù),最后根據(jù)更新策略,將數(shù)據(jù)回寫到磁盤
-
Undo log:記錄了事務(wù)開(kāi)始之前的記錄,可用于事務(wù)失敗后的回滾

